AI observability for LLMs in 2026: what enterprise teams actually need (and what most platforms miss)

The AI observability market is flooded with platforms repackaging ML monitoring under a new name. Here is what enterprise teams actually need and the criteria that separate real observability from theater.
Over the course of our careers, we have been inside more than 500 organizations and assessed hundreds of AI systems. I have been in rooms where engineering teams showed me their monitoring dashboards with genuine pride. Slick uptime graphs, latency charts, error rates in healthy green. And I have had to be the one to tell them that none of those metrics told them what Was actually happening.
The monitoring was real. The observability was absent.
Understanding the difference between AI monitoring and AI observability is the starting point for every enterprise evaluation. In 2026, that distinction matters more than ever. The AI observability market is growing fast and conflating terms faster. Here is the hard truth: platforms that were built for statistical machine learning models are rebranding themselves as AI observability tools without changing what they measure. Enterprise teams shopping for solutions are being handed the same toolkits that failed to catch the last wave of AI failures, now with a new logo and tagline on the front.
This post breaks down what AI observability actually means for LLM-based systems, why traditional ML monitoring is not sufficient, and what the six criteria are that enterprise teams should be using to evaluate any platform in this space.
The core problem: Most AI failures in production are not caused by initial model defects. They emerge gradually through behavioral drift that monitoring tools designed for statistical pipelines are structurally unable to detect.
What the market is calling AI observability and why most of it is not
The term "AI observability" entered mainstream enterprise vocabulary around 2023, borrowed from software engineering where observability describes the ability to understand a system's internal state through its external outputs. In software and networking, that means logs, metrics, and traces. In AI, the concept is sound. The execution is often not.
The majority of platforms currently marketing themselves as AI observability tools are tracking one or more of the following: input data distribution, prediction accuracy against ground truth labels, model latency and throughput, infrastructure uptime, and pipeline data quality. These are all legitimate engineering concerns. None of them tell you how a large language model is behaving, whether it is drifting, or whether it is creating harm.
This is not a minor gap. It is a categorical mismatch with real consequences. Traditional ML monitoring was designed for a world where a model produces a numerical output, a score, a classification, a probability, and you can measure whether that output is drifting from a known-correct baseline. That framework breaks down entirely when the model produces language.
Language outputs are not numerical. Behavioral drift in an LLM shows up as subtle shifts in tone, changed refusal patterns, semantic inconsistency across similar queries, and altered reasoning pathways. None of those register on a latency dashboard or a data distribution chart.
The gap between what enterprise monitoring tools measure and what actually causes AI failures and harm in production is not a tuning problem. It is an architecture problem.
Your model passed validation. Your monitoring is green. And your AI has been slowly becoming someone else.
The difference between AI monitoring and AI observability
AI monitoring tracks whether a system is running. AI observability tells you how a system is behaving. For deterministic software, that distinction is narrow. For large language models, it is everything.
ML monitoring was designed for models that produce bounded, predictable outputs. You set a baseline, you measure deviation, you alert when thresholds are crossed. That approach works when the output space is finite and measurable. It does not work for LLMs, because LLMs are non-deterministic systems. The same input can produce meaningfully different outputs across inference calls, and the space of possible outputs is effectively unbounded.
Non-deterministic AI system monitoring requires a fundamentally different architecture than what ML pipelines were built to support. You cannot baseline a probability distribution and call it done. You need to monitor the behavioral fingerprint of the model, what it says, how it frames answers, where it draws its boundaries; continuously against a validated reference point established at deployment.
That is observability. Everything else is uptime tracking with a new name.
What is AI behavioral drift?
AI behavioral drift is the gradual, often imperceptible shift in how a deployed AI model responds over time; without any deliberate retraining or reconfiguration. It is not a model crash. It is not a pipeline failure. It is the slow divergence of a model's production behavior from its approved, validated baseline.
Behavioral drift happens for several reasons: changes in how users phrase queries over time, cumulative effects of context window interactions, model provider updates to underlying infrastructure, and shifts in the surrounding data environment the model operates within. In most cases, no single response looks wrong. The drift is visible only when production outputs are compared systematically against what the model was doing at deployment.
This is why AI model inconsistent outputs are one of the earliest observable symptoms of behavioral drift in production, and why inconsistency across similar queries should be treated as a governance signal, not just a performance anomaly. A model that answered a compliance-relevant question one way at deployment and answers it differently six months later has drifted. Whether that drift is harmful depends on what changed. Knowing that it happened at all requires behavioral observability.
What ML monitoring actually tracks and where it stops
To be precise about what we are comparing, here is what traditional ML monitoring tools were designed to do well:
- Data drift detection. Monitoring whether the statistical distribution of input data has shifted relative to training data. Useful for models where input patterns are predictable and bounded.
- Model accuracy degradation. Tracking whether prediction accuracy against labeled ground truth is declining over time. Requires labeled outcomes. Most LLM deployments do not have these in real time.
- Infrastructure health. Latency, error rates, uptime, resource utilization. These are engineering metrics, not behavioral metrics.
- Pipeline integrity. Ensuring that data flowing into and out of a model is complete, correctly formatted, and within expected ranges.
Do these capabilities matter? Yes. But they are not the problem. The problem is that none of them answer the question an enterprise compliance team, a risk officer, or a board needs answered: Is this AI system behaving the way it was approved to behave?
That question requires behavioral observability. Behavioral observability requires a fundamentally different approach.
What LLM behavioral observability actually requires
Behavioral observability for large language models requires monitoring the output. What the model says, not just whether it said it. That means establishing a validated behavioral baseline at the point of deployment and continuously comparing production outputs against that baseline across four dimensions:
- Semantic consistency. Is the model producing outputs that remain semantically aligned with its intended purpose and approved behavior? Semantic drift, where a model's meaning shifts even as its vocabulary stays similar, is one of the earliest warning signs of behavioral drift and one of the hardest to detect without purpose-built tooling.
- Response pattern stability. Are the model's response patterns, structure, length, framing, and format, consistent with validated behavior? Significant shifts in how a model constructs responses often precede more consequential behavioral changes.
- Refusal rate and boundary behavior. Is the model refusing to answer questions it previously answered, or answering questions it previously refused? Refusal rate drift is a governance-critical signal. Changes in where a model draws its behavioral boundaries are exactly what regulators under the EU AI Act and ISO 42001 need documented.
- Tone and sentiment deviation. Has the model's affective register shifted? Tone deviation, a model becoming measurably more or less confident, more or less hedged, more or less emphatic, is a behavioral signal that traditional monitoring does not capture at all.
What behavioral observability requires: A validated behavioral fingerprint established at deployment, continuous production output monitoring against that fingerprint, and governance-ready documentation of any detected drift, structured for ISO 42001, EU AI Act, and sector-specific compliance requirements.
The enterprise gap in 2026
Enterprise AI deployments in 2026 are operating under a compliance environment that did not exist two years ago. The EU AI Act is in force for high-risk AI systems. ISO 42001 is becoming a procurement requirement in financial services, healthcare, and government. The SEC has issued guidance on AI disclosure. And enterprise legal and risk teams are no longer treating AI monitoring as an engineering responsibility. They are treating it as a governance obligation.
The problem is that the tools available to most enterprise teams were not built for this environment.
They were built to answer: "Is the model running?"
The regulatory environment now requires answering: "Is the model behaving as approved, and can you document that it is?"
Those are completely different questions. They require completely different tools.
The risks of deploying an AI model without continuous behavioral monitoring now include regulatory exposure, not just engineering failure. Organizations that cannot demonstrate continuous behavioral conformance are not compliant with ISO 42001, regardless of what their engineering dashboards show, and under the EU AI Act, that gap carries direct legal consequence for high-risk AI deployments.
The compliance exposure: ISO 42001 requires ongoing monitoring of deployed AI systems, not just validation at launch. Organizations that cannot demonstrate continuous behavioral conformance are not compliant, regardless of what their engineering dashboards show.
Six criteria for evaluating AI observability platforms in 2026
Based on hundreds of AI system audits and the drift data collected by Fusion Sentinel across available frontier models, here are the six criteria that separate genuine AI observability platforms from repackaged ML monitoring:
- Behavioral baseline capability. Does the platform establish a validated behavioral baseline at deployment, not just a statistical snapshot of input data? The baseline is the reference point. Without it, you are monitoring drift with no reference for what the model was supposed to be doing.
- Semantic output monitoring. Does the platform monitor what the model says, semantic content, not just whether outputs were produced? Platforms that monitor only throughput and latency cannot detect behavioral drift.
- Governance-ready documentation. Does the platform produce documentation that can help satisfy ISO 42001 ongoing conformance requirements and EU AI Act post-market monitoring obligations? Engineering dashboards are not compliance documentation.
- Drift alerting with configurable thresholds. Can compliance and risk teams configure drift thresholds that align with their governance policy, not just engineering performance bounds? Behavioral drift thresholds are a governance decision, not an engineering one.
- Audit methodology alignment. Is the platform's monitoring logic developed and validated under AI governance audit methodology? Platforms built purely by engineering teams optimize for detection. Platforms built under audit methodology optimize for defensibility, which is what regulatory reviews require.
- Readable by non-engineers. Can compliance officers, GRC teams, legal counsel, board members, and the public read and use the platform's outputs, or does everything require a data scientist to interpret? Enterprise AI governance is not an engineering function. The tooling cannot be either.
Where Fusion Sentinel fits
Fusion Sentinel is the AI observability platform Fusion Collective built because we have personally experienced algorithmic bias, witnessed irreparable harm go unanswered, and found that the tools we needed to proactively address these gaps simply did not exist. After hundreds of AI system audits and that lived experience, we knew exactly what behavioral signals mattered, what documentation regulators required, and where every existing monitoring tool fell short.
Fusion Sentinel detects behavioral drift in production LLMs by monitoring outputs, not pipelines. It establishes a behavioral baseline at deployment and continuously compares production outputs against that baseline across semantic consistency, response patterns, refusal rates, and tone deviation. Every monitoring cycle produces governance-ready documentation structured for ISO 42001 and EU AI Act compliance.
It is the only AI observability platform developed under ISO 42001 Lead Auditor methodology. That means it was designed from the start to produce the kind of insights that hold up in a regulatory review, not just the kind that look good in an engineering standup.
Fusion Sentinel
See behavioral drift detection in action
Schedule a demo to see how Fusion Sentinel monitors your production AI models and enables you to produce supporting documentation for ISO 42001 and EU AI Act requirements.
How Fusion Sentinel compares to traditional ML monitoring tools
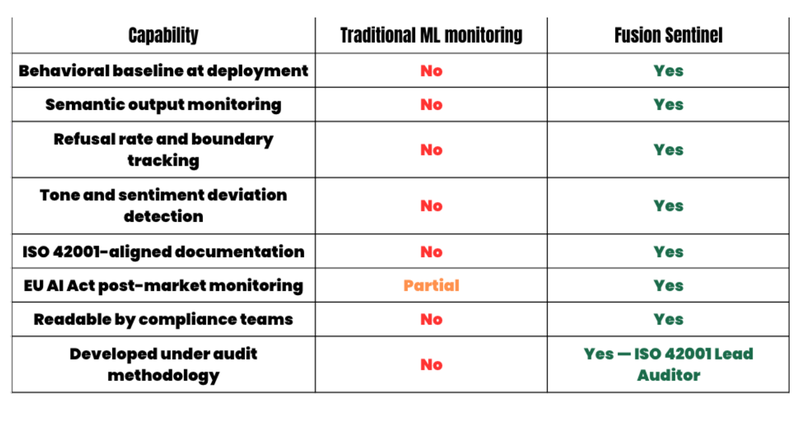
Traditional ML monitoring tools were not designed for LLM behavioral observability. The gap is structural, not a feature deficit.
The bottom line
The AI observability market in 2026 is not short on platforms. It is short on platforms that were designed for the actual problem: how to know, continuously and documentably, whether a production AI model is behaving the way it was approved to behave.
ML monitoring solves an engineering problem. AI observability, real AI observability, solves a governance problem. Those are not the same problem. The tools are not interchangeable. And in a regulatory environment where the question is no longer "is your model running" but "can you prove it is behaving," the difference is not academic. The difference is liability.
The best AI observability platforms for enterprise in 2026 are the ones built by people who have been inside the audit room and know what documentation regulators actually require.
Share this article
Related Articles

The Reskilling Illusion: When AI Transformation Means "You're Fired"
Oct 03, 2025
